
by admin | Jan 18, 2021 | Automation Testing, Blog |
The rise of AI-powered software, test automation, and data-driven tools are revolutionizing multiple industries with their ability to expand the depth and scope of developing products. When done right, these testing applications can maximize human talent by minimizing efforts, spotting bugs, and ironing out inefficiencies to ensure a high return on your investment.
While it strives to boost productivity and take over menial tasks, it’s crucial to note that not all software testing tools are the best pick for the job. There is a myriad of choices available in the digitally-oriented market, so choosing the right one suited for the project can make all the difference in the tool’s apt success.
With that in mind, the list below explores some game-changing factors worth considering when shopping for the best tools that can guarantee maximum efficiency, accuracy, and effectiveness for your needs:
Factor #1: Platform Compatibility
One of the biggest challenges you need to consider when selecting an automation tool is to ensure it can support your application. Keep in mind that many automated testing tools only support .NET or Java applications, so be sure to choose the right one that can cater to your company’s applications and platforms. After all, it will be a moot and expensive effort to use a testing tool that can’t support your application needs!
Factor #2: OS Compatibility
Locking your application to a specific OS for years to come can limit your reach in the market, so it helps to choose an automated testing tool that can support a myriad of OS versions, especially when it comes to OS compatibility. Not to mention, QA engineers also recommend testing across multiple operating systems to ensure it runs smoothly for different consumers in the future.
Factor #3: Scriptability
QA engineers highly benefit from scriptable software since it leaves plenty of room to expand, automate, and create a custom interface. With that in mind, choosing an automated software testing tool that can understand various scripting languages offer flexibility that can further streamline the process.
Factor #4: Reporting Capabilities
The primary purpose of a software testing tool is to help you identify gaps in the development phase that you can fix to improve the experience for end-users, so it’s only logical to prioritize the automated tool’s ability to send comprehensive reports regarding the project’s performance. This includes extensive details such as the result log, graphic reporting, informative alerts, warnings, and more.
The Bottom Line: The Importance of Selecting the Best Automation Tool that Suits Your Unique Needs
The right software test automation tool can help your developers build successful and accurate testing, allowing you to optimize your resources and extend the scope of manual testing in more ways than ever.
Why Choose Codoid?
If you’re looking for a reputable automated software testing company in the USA, then get in touch with our QA experts! We offer some of the best app testing services that can ensure the tools you use are the perfect fit for your project. Contact us today at +1 888-878-6183 to see how we can improve your software’s performance in more ways than one.

by admin | Dec 10, 2020 | Automation Testing, Fixed, Blog |
Nowadays, Knowledge of Continuous Integration tools is a must-have skill for an automation tester. Continuous Integration (CI) and Continuous Delivery are automated approaches to produce applications effectively & reliably. The process of Continuous Integration is set up through a pipeline. Each step has its own rules and conditions.
Suppose a test automation engineer wants to configure automated scripts that validate the functionalities before & after deployment. In that case, he/she should be familiar with the continuous integration tool used by your project team.
Some project teams use separate code repositories for automation testing. Suppose you have the automation test scripts in the application code repository. In that case, everyone in the group can utilize the automated test suite, and as an automation tester, you will also understand how the code is flowing in the pipeline.
In this blog, we have listed the most popular Continuous Integration Tools.
Jenkins
Jenkins is the widely used Continuous Integration tool. Since it is an open-source tool and easy to use, everyone loves it. If you are looking for Jenkins Enterprise support, you can approach CloudBees, the company which created Jenkins. The power of Jenkins is it has over 1500+ plugins.
If Jenkins’ base functionalities don’t satisfy your needs, you can search for suitable plugins to accomplish the intended setup.
Nowadays, in every automation tester’s profile, Jenkins is mentioned as one of the technical skills.
Bamboo
Bamboo is a commercial CI tool. If your team is a fan of Atlassian products and wants a close integration with Jira, Bamboo is right. You can add free & commercial plugins from Atlassian Marketplace.
Bamboo allows you to configure pipelines using Web UI or spec files. The supported file formats for spec file configurations are YAML and Java.
TeamCity
TeamCity is one of the products from JetBrains. You can use up to 100 builds and three agents from the free license. The advantage of TeamCity is it allows you to view and configure pipelines from JetBrains IDE and Visual Studio.
You can purchase more agents when the need arises and configure pipelines in XML or Kotlin files.
GoCD
GoCD is a free and open-source continuous integration tool. GoCD allows you to configure pipelines in XML, JSON, and YAML formats.
Travis CI
Travis CI is free for open-source projects. If your open-source code is in Github and is looking for a useful CI tool, Travis will be the go-to choice. Travis CI allows you to extend its capability with third-party applications, clients, tools, and libraries.
Codeship
CodeShip is a cloud-based CI tool. It comes in two plans – CodeShip Basic and CodeShip Pro. You can configure pipelines on Web UI in a basic plan, and the tasks will be run on reconfigured Docker containers. If you want customized containers to run the tasks and YAML file based configurations, you will have to go for the CodeShip Pro plan.
Codeship Basic plan is free up to 100 builds per month with unlimited user access. The pro plan’s pricing is calculated based on the number of builds and VMs you will use.
CircleCI
CicleCI uses a variety of Docker containers. For mobile app development, CircleCI provides images to build & test Android applications. In the free plan, you will get 1000 build minutes per month with one container.
In Conclusion
As one of the leading software testing companies, we have used various CI tools to execute automation test suites. However, for building the freeware products developed by Codoid, we use the Jenkins CI tool.
In this blog article, you have just learned necessary information about the popular Continuous Integration tools. When you go through the pipeline details on the CI tool, you will know the importance of the automation test scripts and their use.

by admin | Nov 13, 2020 | Automation Testing, Fixed, Blog |
In the software industry, QA or quality assurance is vital in ensuring app rollouts that reach a certain standard. At this stage in development, a business might hire a software testing company to ensure the product’s accuracy and reusability. QA is when the software team detects and corrects bugs, checks reporting capabilities and resource efficiency, and ensures they have end-to-end optimization.
Automated testing services are becoming popular today and are changing the industry for the better. Automation testing companies run these quality checks for regression testing, user environment simulation, and others. Before diving into why some people are automating this process, it helps to know more about it.
Why automate quality assurance processes?
Traditionally, humans are responsible for QA. QA covers everything from minor rendering glitches to security vulnerabilities, so it’s essential to have a team that can respond to and rectify a range of issues.
Automating tests does not eliminate the need for manual testing services since you still need experts to analyze results. According to software developers, DevOps, Lean, and Agile are things to watch for in the coming months or years.
As a result of these trends, the entire software development team would be responsible for quality assurance; it will not rely solely on QA testers in the future. Problem-solving and critical thinking will inform the majority of these teams’ tasks.
When you use test automation services, you reduce maintenance costs and get a higher ROI. In manual software testing, it is easy to commit errors, especially in apps with several hundred lines of code. Automation takes care of repetitive tasks and executes these rapidly.
Furthermore, automation tools can report and log test scripts to show their status to users. Comparing the results of these reports to others will give development teams a more accurate picture of how the software operates and shows whether the app fulfills the requirements it needs to.
What does automation look like for QA?
QA automation starts with creating a folder structure that enables easy tracking of items. Aside from ensuring quality, this process is concerned with portability, syncing folder hierarchies with different drive locations and types of applications.
When you deploy automated tests, you also address errors and recovery scenarios within the framework instead of the script. Frameworks are environment-independent; you can configure your operating system or browser to ensure that you don’t need to touch the scripts to update test data. Furthermore, automation means being able to test in batches and capture results in screenshots, which lets you understand in greater detail any defects that you might encounter.
You can have automated testing for both GUI and API, enabling you to eliminate human variables in evaluating the app’s effectiveness, response time, and accuracy. It’s possible to document everything from scripting guidelines to naming conventions and more.
Conclusion
Whether you’re developing a testing plan for an in-house team or using SaaS from an automation testing company, quality assurance lets you continuously improve your framework and take it to maturity. When you automate some processes, you reduce the number of hours your team puts into the manual effort, making them more productive and preparing them for complex, higher-order tasks like strategizing and planning.
For grade-A testing that meets the mark, turn to Codoid today. We are a leader among automation testing companies, and we have provided insights and analyses for more than 700 app development teams. Schedule a consultation today to learn more!

by admin | Nov 2, 2020 | Automation Testing, Fixed, Blog |
Technology has enveloped the world with its blanket charm, and we are in no position to the benefits it endowed on us. From the first computer to the latest smartphone, the world has transformed into an accessible place for us. Earlier, what was considered strange and unknown is now familiar and mundane. Technology is something that is treated as a democratic resource at best, available for all people. Automation testing might look like it is an unsuitable investment, but instead, it will go a long way. If the faults and risks are corrected and cemented at the root level, it might be a great asset for human civilization.
But what uses is this technology and software if it can’t enhance itself to suit all people at all times? The need of the hour is inclusivity in all fields which assist everyday human lives. In that case, technology should fill disparity and deformity. For people with challenges, we need more integrated and developed strategies for tests.
Automation Testing Improving Process & Result
Automation testing is a way of Software testing technique to test and compare the actual result with the required outcome. This can be accomplished and won over by writing test scripts or using any automation testing tool. Automation testing is used to automate repeated and habitual tasks and other testing tasks, which are tricky to achieve manually.
The strategy of automating your software tests comes with a myriad of benefits. Not only does this habit help eliminate various complexities and errors seen with manual testing, which is operated entirely by a person, but automation can also improve and better the user experience and give your product launches a streamlined structure.
However, with every advantageous approach comes linked to associated risks. Several issues can show up during test automation that can lead to other problems if the team is not prepared. These risks aren’t enough reason to hamper a concept; they can be uprooted fundamentally and improved upon. Let’s look at ways in which we can lower such risks and make automation a better experience for all users-
Automation testing chances point to costlier expenses
Often, difficulties with test automation come down to the project’s bottom line. According to a National Institute of Standards and Technology study, inadequate testing processes direct to considerably high software developers’ prices. Wasteful methods and tools cost the American economy anywhere from $22.2 billion to $59.5 billion annually. Much of these costs are acquired by the development organization, which has to carry out extra tests due to software malfunctions or mitigation methods. Twenty-five to ninety percent of software development resources are spent on testing; there is often no room in the budget for unplanned, consequent tests.
To prevent exceeding budgets and complete extra tests, testing teams must avoid the typical pitfalls that lead to added testing needs. Efficient testing means grabbing application performance and other issues on the first go-around, so team members must know exactly what they’re searching for.
Develop clarity in your goals and how to reach them
It’s also necessary to have a well-defined list of objectives in place before tests are carried out. These will help inform the tests themselves and guide the team through their insights from these tests. For each automated test, stakeholders should fully understand what they hope to achieve and what steps they will take after seeing the test outcomes. Making a list of clear goals that you’ve established ahead of time will streamline overall testing processes and ensure that the project remains on schedule.
Automation: Not a replacement for manual processes
While automated testing is undoubtedly a positive thing, it is by no means a replacement for human exploratory testing. Teams will be required to leverage manual and automated software testing to guarantee the product is ready for launch. A blend of testing types and levels is required to achieve the desired quality and mitigate the uncertainty associated with defects.
Guaranteeing stability before the automation testing process
When it proceeds to automated testing, timing is everything – the appeal must be developed and durable enough to stand up to the experiments’ demands. Even in flexible environments, it’s necessary to ensure stability before carrying out automated tests. Skipping this step could lead to initial test results and added work for both developers and testers. For this purpose, it’s significant to time tests at essential points during the process, particularly for rapid developments.
The execution of automated tests should be consistent
It’s also important to keep in mind that automated testing is not a one-and-done process. Tests must be carried out consistently to gain all the benefits this approach offers. This has the conclusion of highlighting crashes and presenting constant feedback about the health of the arrangement. Automated tests are initiated through the incessant integration system instead of manually to support this. Otherwise, the risk of irregular test runs increases.
Leveraging skillful means is significant
Software Testing Help noted that it’s essential to have a knowledgeable team in place when carrying out automated tests. Stakeholders with expertise in automated testing and programming and development can help the initiative be successful. But, experienced sources don’t just reach the team itself. Testing teams and quality assurance must have a robust solution in place to help them manage tests and collaborate in real-time. Thus, it is imperative to have a test management strategy that fits the bill and provides users with the ability to maintain multiple projects at once and manage both automated and manual testing.
Automation testing might seem like a faulty dream currently because of the risks it houses. For a world that works on manual demands, technological labor is worth living for all human beings. Imagine a world accessible to people of all kinds because technology is available and workable in such a world.
These ways assist you in ways that help you in getting a much more enhanced experience of technology and its various ways of supporting human endeavor through automation testing. You can contact Codoid for all automation testing services!

by admin | Apr 19, 2020 | Automation Testing, Fixed, Blog |
As a software testing services company, we encounter many test automation challenges. In this blog article, we would like to list a few useful Python Test Automation Tips, With the hope that you will bookmark this article for future references.
Installing PIP on Windows
Installing PIP on Windows is a simple task and an One-time activity. When you are setting up a test bed for test automation scripts execution, you need to recollect the steps to install PIP on Windows.
Step #1 – Download get-pip.py
Step #2 – Run get-pip.py
Virtual Environments on Windows
Installing, creating and activating a Python virtual environment is pretty straight forward. On the contrary, when you play around with multiple OS, you must be aware of the fact that there are different steps involved to activate a virtual environment on Windows.
Step #1 – Install virtual environment package
Step #2 – Create a virtual environment
Note: In the above command, newenv is the environment name.
Step #3 – Activate the virtual environment. Go to the virtual environment folder on Command Prompt, navigate to ‘scripts’ folder, and run ‘activate’ command.
Creating requirements.txt
Managing the required Python packages in requirements.txt is a best practice. If you have already installed the required packages and want to create requirements.txt, then run the below command.
pip freeze > requirements.txt
Note: Once the command is executed successfully, it creates the requirements.txt with the list of installed packages.
Behave JSON Report Generation
If you are using behave BDD framework and would like to generate JSON report after automated script execution, then kick-off the behave execution using the below command.
behave -f json -o reports.json
Customized PDF Report Generation
Publishing readable and useful report is one of the important test automation success factors. You can create customized PDF report using behave JSON report. Refer the following URL for more details – Customized Test Automation PDF Report. You can create PDF report as shown below using pdf_reports package & Pug template.
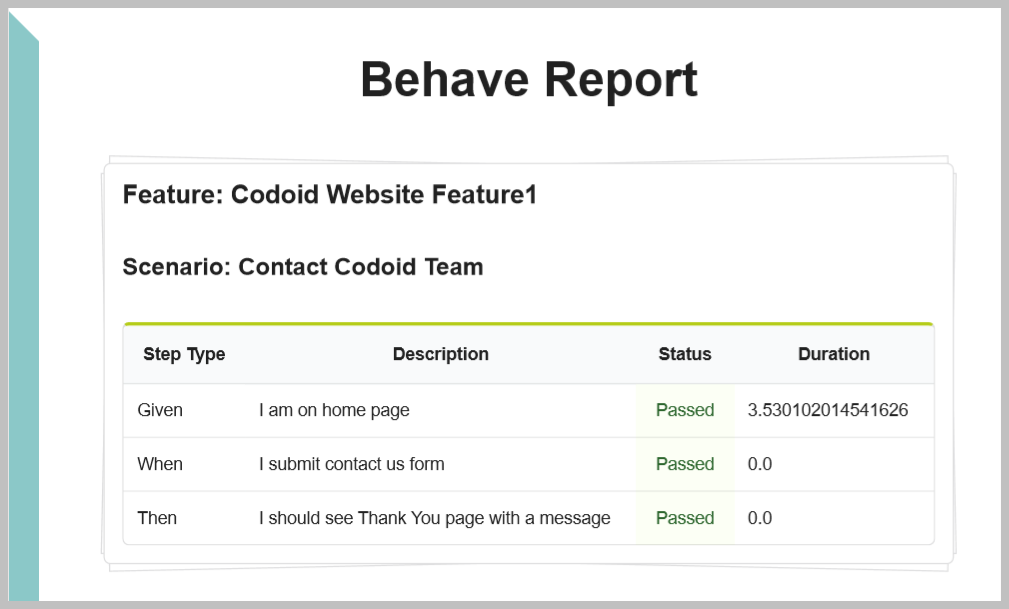
Python Selenium Headless Chrome
Starting Chrome in headless mode using Selenium WebDriver can be done using ChromeOptions. Refer the below Python snippet.
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('headless')
driver = webdriver.Chrome(executable_path='chromedriver.exe',chrome_options=options)
Behave Teardown
In most of the BDD frameworks, you need to write setup and tear-down in two different methods. However, in behave framework, you can write both in one method. Refer the below snippet.
from behave import fixture, use_fixture
from selenium import webdriver
@fixture
def launch_browser(context):
#Launch Browser
context.driver = webdriver.Chrome(executable_path='driverschromedriver.exe')
print("=============>Browser is launched")
yield context.driver
#Clean Up Browser
context.driver.quit()
print(context.scenario.duration)
print("=============>Browser is quit")
def before_scenario(context,scenario):
the_fixture1 = use_fixture(launch_browser, context)
Network Throttling
In Selenium WebDriver, you can set network upload & download throughput and latency to run the automation testing scripts in different network conditions.
driver.set_network_conditions(
offline=False,
latency=5, # additional latency (ms)
download_throughput=500 * 1024, # maximal throughput
upload_throughput=500 * 1024) # maximal throughput
Desktop App Automation Testing
Using pywinauto package, you can automate Desktop App Test cases.
from pywinauto.application import Application
app = Application().start("notepad.exe")
BuildBot CI
If you want to manage all CI related operations using Python code, you can try BuildBot CI.
In ConclusionAs an automation testing company, we use Python and Selenium WebDriver for multiple projects. We hope you have gained incredible insights about various test automation tips that’s has been shared in this blog article, As a continuing trend we will be keep sharing more and more useful automation testing related articles in the coming weeks.

by admin | Jun 10, 2020 | Automation Testing, Fixed, Blog |
Software testing ensures your product meets all customer requirements and addresses each product risk with a proper test plan. Testing can uncover failures of many kinds, and in today’s agile world, automation testing is a part of the work to be done for the story and the benefit of test automation is quite obvious. A properly planned testing process is a must for ensuring the required level of software quality without exceeding a project’s time and budget.
Testing is no longer a one-time task but a continuous process. An estimate is a prediction, it could be an approximation of what it would cost, or a rough idea of how long a task would take to complete. Better testing estimates allow for more accurate scheduling, realize results more confidently, and form the foundation of good management credibility.
Estimating testing in the contemporary world of agile and DevOps demands some new rules. Stories with dozens of tasks that lack the value definition for intended users is not helpful. One need to consider the effort required for test design, test implementation, test execution, and the effort to automate while estimating the story. Especially when you are conducting an automation testing to reduce the cost and time, you should consider the below estimation techniques.
Scope usually means finding the right test cases for automation. The deciding factor for any test to be automated is linked with how many times that particular test can be repeated. When new functionalities get added or if there exist any modification in existing functionality then the automation scripts need to be added/ modified, reviewed and maintained for each release cycle.
• Split the application into separate modules and analyse each module to determine possible testing options
• Prioritize the list of modules and assess the history of each and every test case (as many of the test cases may not have been run often enough to get into the right priority)
• Analyse and classify the Test cases into various categories like API, Web, DB etc and choose the ideal candidate for automation
• Identify the complexity of the test case like Number of verification point or check points for each of the test cases
• Calculate the ROI for the identified test cases
Selecting an automated testing tool is essential for test automation. There are plenty of automated testing tools available in the market, it is important to choose the automated testing tool that best suits your overall requirement. Consider the below factors when selecting the automation tools
• Understand your project requirements and identify the scenarios you want to automate.
• Finalize the budget for automation and search the tool that suits your requirement.
• Compare and choose the tools that fall well within your budget and easy utilisation.
• Check for Logging and Reporting mechanism
• Underlying language which is used to build automation script and check for the feasibility of integrating with the build tools
Below is the combination of tools selection for framework development:
1. Eclipse / RAD – as IDE
2. Ant / Maven – As build tool
3. jUnit / TestNG – as unit test framework
4. Log4j – as Logger
5. ReportiNG – as reporting tool
6. Text files – for tracking the environments/credentials
7. Excel files – for tracking the test data
8. Perl / Python – for setting up an environment and triggering the test scripts.
Framework implementation means designing input files like Excel / JSON / XML etc, designing folder structure, implementation of logger, utilizing build tools and environment related data and credentials.
Framework means a real or conceptual structure created to provide support or guidance to an entity that could expand in future. In simple terms, a test automation framework can be defined as a set of processes, standards and interactions between the components in which scripts are designed and executed. While implementing a framework one should consider handling scripts and data separately, reuse of code, high extensibility, library creation and maintainability.
Test Case ComplexityWe classify the Test case based on the complexity of the Test case and the complexity of the test case is based on four elements including checkpoint, precondition, test data, and types of test case, which effectively assumes that the complexity is centred at these four elements. Below is the complexity assignment of the test case.

Transactions are measured while hitting /submitting a page / screen. In an ideal scenario a simple Test case should have less than 2 submits or it covers less than 2 navigations from a page. When we read the Test case, we focus on these navigations to calculate the Test case complexity.
Interface complexity

Estimators view and review the user interfaces, API, DB and network to measure the accuracy of the interfaces in providing the service. This complexity describes the external integration/interfaces that are associated with the proposed software. These integrations could be hardware, software, network and communication based on the deployment of the proposed software.
Verification Points
Verification Points are used to verify whether the value of an Application Under Test matches with the expected value. This output value can be considered as input data for other verification points. The complexity is measured using the Test Conditions, Test Data identification, Test Script preparation and Test Execution.
Listed below are the other variables which we need to consider while estimating

While it is quite obvious that the strategic goal of automation testing is to ensure business value, it is just as essential to articulate it periodically to stakeholders on where we stand in the journey towards it. This can be projected in two broad areas – savings in terms of time and cost. Our estimation approach must be dynamic and responsive to changing requirements with the various variables and components described above and the effort is calculated based on test design, test implementation, test execution, and the effort to automate. I hope this will give a head start to those who are seriously considering to calculate the automation testing effort estimation.

































